Using the GitHub API to find open-source projects looking for contributions
Introduction
tl;dr you can find the results of the help-wanted script here, and the code used in this post here.
I wanted a way to discover open-source projects to contribute to. I ended up creating a little script to query the GitHub REST API to search for open issues with the help-wanted tag, as described here. This post just steps through some of that code, and definitely isn't a REST API tutorial! The first thing we'll do is create a simple query, looking for all issues for the R language:
import requests
import pandas as pd
# Define the API URL -- searching issues
url = "https://api.github.com/search/issues"
# Define a simple query: Looking at the R language
params = 'q=language:r'
# Make the API request
res = requests.get(url=url, params=params)
# Show the returned dictionary
res.json()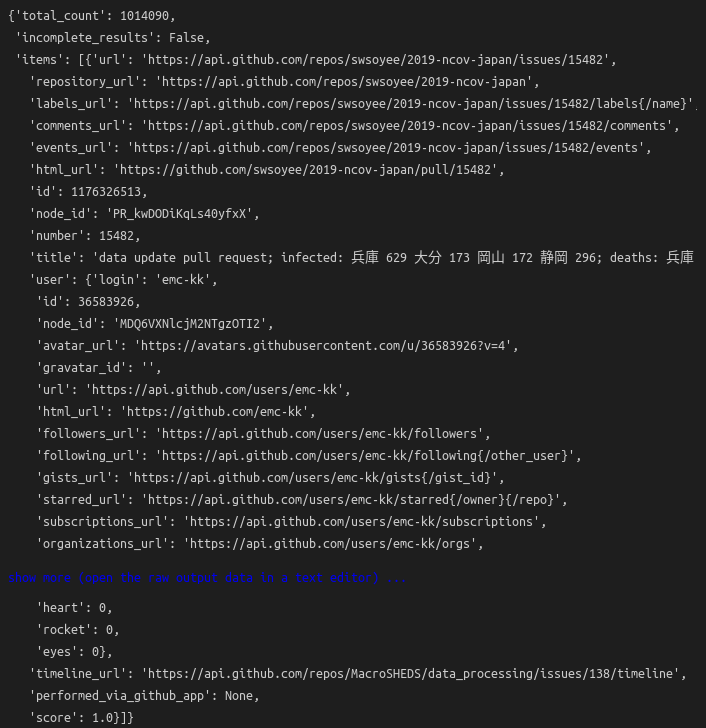
We can see that we've returned a JSON dictionary object, and the interesting parts are in the items key. The total_count key shows around a million issues. Remember that we haven't specified much, just that issues are related to R. We haven't even filtered
on open issues yet. To do that, we can add +state:open to the query, resulting in the following:
params = 'q=language:r+state:open'
res = requests.get(url=url, params=params)
res.json()["total_count"]
[1] 186332
So, from over a million total issues, less than 200,000 are still open. That sounds about right, I guess?
Next, we'll limit to open issues with the "help wanted" tag. This seems like a good tag to filter on if we're looking for things to contribute to, right? We could also look for tags like "good for first time contributions", and so on, but we'll just stick with "help wanted" here.
params = 'q=language:r+state:open+label:"help+wanted"'
res = requests.get(url=url, params=params)
res.json()["total_count"]
[1] 2256Nice! 2256 open issues with the "help-wanted" label for the R language. That
seems like a good place to start. Now, remember that the items
part of the dictionary is where the issue data is kept, so, for example,
if we look at the keys of the first item, with res.json()["items"][0].keys():

Now we're starting to see some useful information! There are a bunch of URLs, the title of the issue, the text of the issue itself, dates and times, and so on. For my purposes, I'm only interested in a few of these, and after some digging, settled on the following four keys:
[res.json()["items"][0][x] for x in ['title', 'html_url', 'labels', 'updated']]
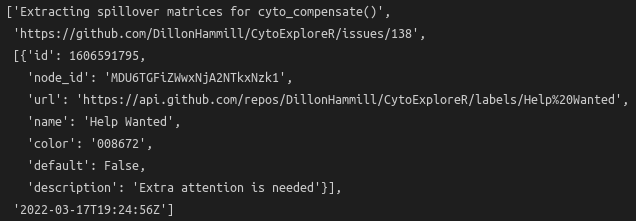
We're pulling out the issue title, URL, last updated date, and a list of dictionaries for the labels. The latter makes things a bit more complicated, but we're really only interested in the name key of this dictionary, so that's all good.
It's all very well to do this for one item, but we're intending to scrape a bunch of open issues to find suitable ones to contribute to, so we'll construct a loop. There are probably much better ways to do this, but I'm just creating four lists to hold the data we want, and then looping over the items to append to those lists. Finally, we chuck those lists into a pandas data frame and we're pretty much done.
titles = []
urls = []
labels = []
updated = []
for i in res.json()["items"]:
titles.append(i["title"])
urls.append(i["html_url"])
updated.append(i["updated_at"])
these_labels = [x["name"] for x in i["labels"]]
toadd = ", ".join(these_labels)
labels.append(toadd)
tbl = pd.DataFrame(
{
"Title": titles,
"URL": urls,
"Labels": labels,
"Updated": updated
}
).sort_values("Updated", ascending=False, ignore_index=True)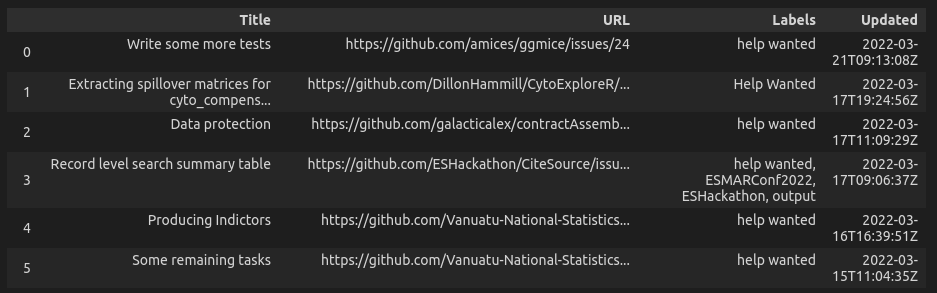
One thing to note is that the default number of returned items is 30. We can increase
this to 100 with "&per_page=100" at the end of the query, and to
return more than that, we'll need to search specific pages of the results.